KTHW - Set up networking with Weave Net.
August 2, 2020 - Reading time: 10 minutes
We now need to set up a CNI plugin that will allow us to have east-to-west traffic between pods.
The worker nodes need to allow IP forwarding
sudo sysctl net.ipv4.conf.all.forwarding=1
echo "net.ipv4.conf.all.forwarding=1" | sudo tee -a /etc/sysctl.confWe'll download an auto-generated configuration from Weave for our specific version of Kubernetes, and for a a Cluster CIDR of 10.200.0.0/16.
cloud_user@ctl01:~$ curl "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')&env.IPALLOC_RANGE=10.200.0.0/16" -Lo weave.conf
cloud_user@ctl01:~$ grep kind weave.conf
kind: List
kind: ServiceAccount
kind: ClusterRole
kind: ClusterRoleBinding
kind: ClusterRole
- kind: ServiceAccount
kind: Role
kind: RoleBinding
kind: Role
- kind: ServiceAccount
kind: DaemonSetThe file is of kind: List that creates a new role for Weave. The role is added to the kube-ssytem namespace:
cloud_user@ctl01:~$ kubectl get ns
NAME STATUS AGE
default Active 14d
kube-node-lease Active 14d
kube-public Active 14d
kube-system Active 14dThe config file then launches a DaemonSet - A DaemonSet ensures that all (or some) Nodes run a copy of a Pod. As nodes are added to the cluster, Pods are added to them. As nodes are removed from the cluster, those Pods are garbage collected. Deleting a DaemonSet will clean up the Pods it created.
The DaemonSet will download and install two containers in both worker nodes:
kind: DaemonSet
...
labels:
name: weave-net
namespace: kube-system
spec:
...
containers:
- name: weave
command:
- /home/weave/launch.sh
...
- name: IPALLOC_RANGE
value: 10.200.0.0/16
image: 'docker.io/weaveworks/weave-kube:2.6.5'
...
image: 'docker.io/weaveworks/weave-npc:2.6.5'
resources:
requests:
cpu: 10mTo apply the configuration:
cloud_user@ctl01:~$ kubectl apply -f weave.conf
serviceaccount/weave-net created
clusterrole.rbac.authorization.k8s.io/weave-net created
clusterrolebinding.rbac.authorization.k8s.io/weave-net created
role.rbac.authorization.k8s.io/weave-net created
rolebinding.rbac.authorization.k8s.io/weave-net created
daemonset.apps/weave-net createdVerify that the new pods were created with:
cloud_user@ctl01:~$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
weave-net-979r7 2/2 Running 0 6m14s
weave-net-xfnbz 2/2 Running 0 6m15sEach one of the pods was created in a different worker node. And it has two containers. For example, on wrk01:
cloud_user@wrk01:~$ sudo ls -l /var/log/pods/kube-system_weave-net-xfnbz_9*/
total 8
drwxr-xr-x 2 root root 4096 Aug 2 20:44 weave
drwxr-xr-x 2 root root 4096 Aug 2 20:44 weave-npcNow that the pods were created, the new network interfaces were added to the workers:
cloud_user@wrk02:~$ ip -h link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 0a:fa:ab:9d:5b:14 brd ff:ff:ff:ff:ff:ff
3: datapath: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether f2:80:55:b3:75:5f brd ff:ff:ff:ff:ff:ff
5: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 26:ca:30:44:3b:74 brd ff:ff:ff:ff:ff:ff
6: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 92:35:4a:ab:ba:38 brd ff:ff:ff:ff:ff:ff
8: vethwe-datapath@vethwe-bridge: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master datapath state UP mode DEFAULT group default
link/ether 9e:ea:ca:e5:23:fa brd ff:ff:ff:ff:ff:ff
9: vethwe-bridge@vethwe-datapath: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master weave state UP mode DEFAULT group default
link/ether 82:cf:0d:a5:8b:aa brd ff:ff:ff:ff:ff:ff
10: vxlan-6784: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65485 qdisc noqueue master datapath state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 66:6f:b4:6d:b9:d1 brd ff:ff:ff:ff:ff:ff
cloud_user@wrk02:~$ ip -h -4 addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
inet 172.31.26.138/20 brd 172.31.31.255 scope global eth0
valid_lft forever preferred_lft forever
5: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP group default qlen 1000
inet 10.200.0.1/16 brd 10.200.255.255 scope global weave
valid_lft forever preferred_lft forever- wrk02 has 10.200.0.1/16
- wrk01 has 10.200.192.0/16
Creating our first deployment
We can now created a Deployment of two nginx pods, to confirm that a pod IP address is automatically assigned to each pod:
cloud_user@ctl01:~$ cat nginx.conf
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
run: nginx
replicas: 2
template:
metadata:
labels:
run: nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
cloud_user@ctl01:~$ kubectl apply -f nginx.conf
deployment.apps/nginx created
cloud_user@ctl01:~$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7866ff8b79-ktvrs 1/1 Running 0 6m57s 10.200.0.2 wrk02.kube.com <none> <none>
nginx-7866ff8b79-v2n4l 1/1 Running 0 6m57s 10.200.192.1 wrk01.kube.com <none> <none>The Weave logs on the worker nodes shows that two new cluster IP were associated to the pods
2020-08-02T21:06:44.554513018Z stderr F INFO: 2020/08/02 21:06:44.554368 adding entry 10.200.0.2 to weave-k?Z;25^M}|1s7P3|H9i;*;MhG of 064e9bf5-8a47-4c21-8ae9-35557edbdc9a
...
2020-08-02T21:06:45.129688044Z stderr F INFO: 2020/08/02 21:06:45.129574 adding entry 10.200.192.1 to weave-k?Z;25^M}|1s7P3|H9i;*;MhG of a2cb5dee-88a7-474c-9aa4-5bf573dda302The VXLAN set by Weave allows a client running on wrk01 to reach the nginx running on wrk02. The packets are encapsulated inside UDP, and a header includes the unique VXLAN identifier
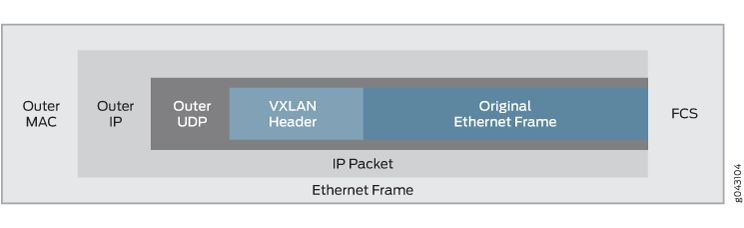
source: https://www.juniper.net/documentation/en_US/junos/topics/topic-map/sdn-vxlan.html
171 15.191593 172.31.26.138 → 172.31.29.196 UDP 126 58287 → 6784 Len=82
172 15.191720 172.31.29.196 → 172.31.26.138 UDP 118 44751 → 6784 Len=74
173 15.191731 172.31.29.196 → 172.31.26.138 UDP 192 44751 → 6784 Len=148
174 15.191735 10.200.192.0 → 10.200.0.2 TCP 68 37224 → 80 [ACK] Seq=1 Ack=1 Win=26752 Len=0 TSval=298244 TSecr=297810
175 15.191737 10.200.192.0 → 10.200.0.2 TCP 68 [TCP Dup ACK 174#1] 37224 → 80 [ACK] Seq=1 Ack=1 Win=26752 Len=0 TSval=298244 TSecr=297810
176 15.191739 10.200.192.0 → 10.200.0.2 HTTP 142 GET / HTTP/1.1Exposing a service
Now we can expose the nginx deployment as a Kubernetes service
cloud_user@client:~$ kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx 2/2 2 2 6d23h my-nginx nginx run=nginxRun the expose command:
cloud_user@client:~$ kubectl expose deployment/nginx
service/nginx exposed
cloud_user@client:~$ kubectl get service -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.32.0.1 <none> 443/TCP 21d <none>
nginx ClusterIP 10.32.0.65 <none> 80/TCP 31s run=nginxTo verify that we can connect to the service, we'll launch a new pod running busybox (BusyBox combines tiny versions of many common UNIX utilities into a single small executable.) - In this example we'll run a modified version of busybox from radial that includes curl
cloud_user@client:~$ kubectl run busybox --image=radial/busyboxplus:curl --command -- sleep 3600
pod/busybox created
cloud_user@client:~$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox 1/1 Running 0 23s 10.200.0.3 wrk02.kube.com <none> <none>
nginx-7866ff8b79-ktvrs 1/1 Running 1 6d23h 10.200.0.2 wrk02.kube.com <none> <none>
nginx-7866ff8b79-v2n4l 1/1 Running 1 6d23h 10.200.192.1 wrk01.kube.com <none> <none>The first attempt to run curl on that the pod returns an error:
cloud_user@ctl01:~$ kubectl exec busybox -- curl 10.32.0.65
error: unable to upgrade connection: Forbidden (user=kubernetes, verb=create, resource=nodes, subresource=proxy)The problem is that the kublet doesn't allow the apiserver (with user CN=kubernetes) to use the kubelet API. https://github.com/kubernetes/kubernetes/issues/65939#issuecomment-403218465
To fix this we need to create a new clusterrolebinding for the existing clusterrole: system:kubelet-api-admin and the kubernetes user:
cloud_user@ctl01:~$ kubectl create clusterrolebinding apiserver-kubelet-api-admin --clusterrole system:kubelet-api-admin --user kubernetes
clusterrolebinding.rbac.authorization.k8s.io/apiserver-kubelet-api-admin created
cloud_user@ctl01:~$ kubectl get clusterrole | grep kubelet-api-admin
system:kubelet-api-admin 2020-07-19T00:20:21Z
cloud_user@ctl01:~$ kubectl get clusterrolebinding | grep kubelet-api-admin
apiserver-kubelet-api-admin ClusterRole/system:kubelet-api-admin 18mThen:
cloud_user@ctl01:~$ kubectl exec busybox -- curl 10.32.0.65 -sI
HTTP/1.1 200 OK
Server: nginx/1.19.1
Date: Sun, 09 Aug 2020 21:18:52 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Tue, 07 Jul 2020 15:52:25 GMT
Connection: keep-alive
ETag: "5f049a39-264"
Accept-Ranges: bytesClean up objects
We can remove the nginx and busybox pods we created to test the CNI.
cloud_user@client:~$ kubectl delete pod busybox
pod "busybox" deleted
cloud_user@client:~$ kubectl delete svc nginx
service "nginx" deleted
cloud_user@client:~$ kubectl delete deployment nginx
deployment.apps "nginx" deleted